Ticker Plant
The idea of a ticker plant is being able to subscribe to ticker feeds and be able to aggregate that data into databases that can be useful. Now there are key items that you must consider when building a ticker plant.
- You can get a million ticks a seconds, that's quotes or trades occuring during a volatile event
- IO or disk writes are slow and depending on your drive, it can take quite a long time to process events into databases
So how should we approach things? Most companies have a disposal of servers and options to to them to handle a large feed of data. I don't... even KDB+ as good as it is can be challenging because I'm just a developer (Yes, a knock to the I'm just a girl trend). So let's think about what we need vs what we don't need.
Fire Hose Of Data
I like to think of the data that comes from liquidity first as a fire host of data you must wrangle to get it down to a managable size. To do this, there are a few things I can employ and a few things I can essentially skip. When I receive a tick, I can pass that on to my pub/sub applications. So stream the data and pass it right onto Redis' pub/sub as well as RabbitMQ's pub/sub system. Cool, that takes care of data I could use later on.
Now for the most part, I don't see the trade/quote data to be meaningful to be besides generating candlestick data. So in memory, in my code I will build real time candlesticks on the fly. You can think of this as building bar 0 for each minute, 15 minutes, 30 minutes, etc... Once a minute completes, we can write that data to a list in Redis. API's can call that list to generate databases for intraday candlesticks. Once the day has complete, we can pull that list and ingest it into our database which will be questdb.
Considerations to take in QuestDb is that sure, it's a fast database and it can handle tons of data because it's a timeseries database that's column based. That's great and all but again, we are limited to IO writes and these days even with M.2 integrations, we can still only write so fast. So at the end of the day, we will run queries on the Redis database to extract out candlesticks we build and fill them into QuestDb for longer timeseries data.
Ticker Management
Let's be honest here, in equities, there are roughly 11-12 thousand tickers you can subscribe to. Now should you? Again, we have to be aware of what we are doing and why we choose this path. I'm not a big time hedge fund, I'm just a developer so limiting what I subscribe to is helpful. To do this, I use screeners. For this, what I aim to use are high volume tickers. You can use what you like but I like TradingView's screener.

This gives me a list of tickers which I can reduce down to. america_2024-11-12_0d963.csv
Now we have effectively reduced our ticker subscription down to around 1-2 thousand tickers. There's just no point in downloading or subscribing to tickers you will never use. Can they do viral and make lots of money? Sure but that's not what I'm aiming for. I'm aiming to build what most people will use, not the niche companies no one has ever heard of.
Additionally when it comes to crypto, the same can be done in filtering. It's unlikely for you to be trading something out an obsecure currency so filter the a base pair you plan to trade in which will reduce the amount of tickers you subscribe to.
Candlestick Generation
My strategy in saving data is as follows:
- Subscribe to tick/quote feed
- Send ticks/quotes through pub/sub system but don't save the data
- In your code, you should store candlestick information to process all ticks through
- On a new candlestick, write the previous candlestick to disk aka QuestDb
- As slowly as possible to manage database resources, backfill candlesticks per timeframe
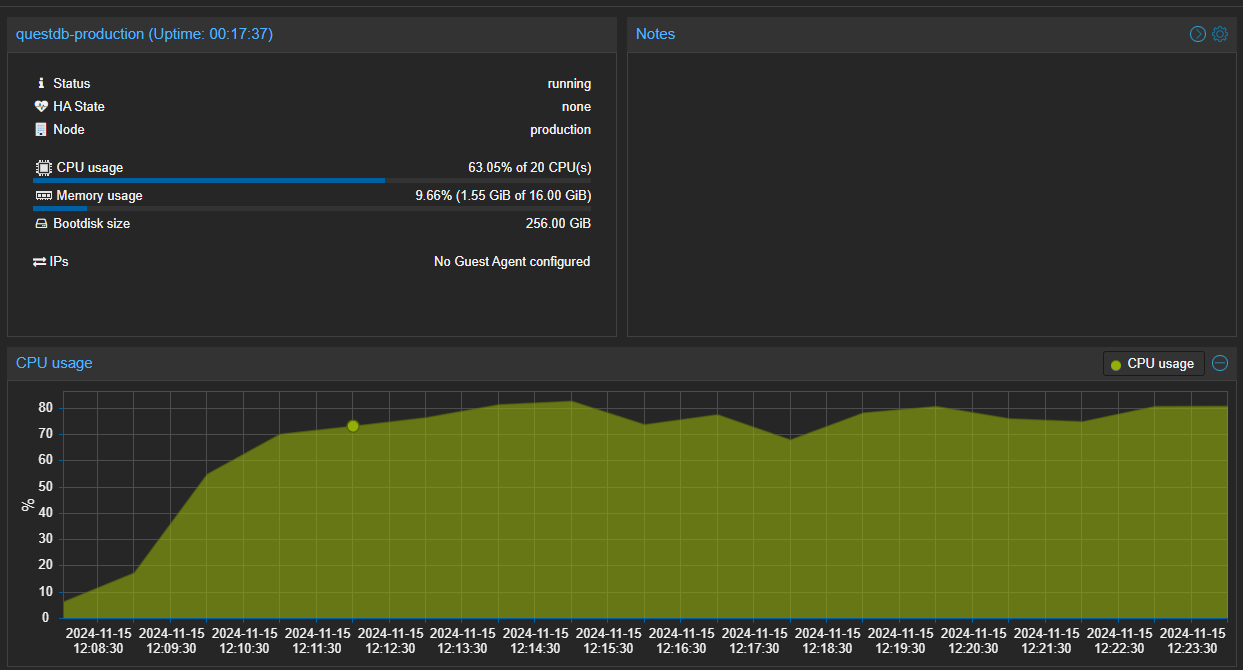
Database management is going to consume the most resources of your server. For example, the below image is actually my server as you have seen configured ingesting data from Alpaca, BinanceUS, Coinbase, Crypto.com, Oanda, and TastyTrade. All have been filtered down to use the least amount of tickers per exchange I want and still as you can see, it's constantly using approximately 80% of a 10 core server. Just think these are just InfluxDb ILP ingestion of candlesticks to QuestDb. It's able to manage it but it's definitely stressing the system. Now on my staging server, it uses about half the amount of CPU usage so something there can definitely be improved.